The Federal Communications Commission (FCC) keeps public records of all satellite actions and license permissions in the central filing system for the International Bureau (IB), MyIBFS. Data analysis of these records may provide insights into patterns of satellite usage trends over time and reveal areas of missing or contradictory information. However, these records are not available in a friendly format.
Thus, we built an application to extract information from HTML data tables, individual web pages, and public notice PDFs. It also performs preliminary cleaning, consolidation, and data validation. The final tabular and .json data files will be fed to an interactive R data application for exploration and analysis.
Table of Contents
Set-Up Environment
These instructions are guaranteed to work on Ubuntu 20.04. It should work for newer versions but you may have to figure out package dependencies by yourself. No packages here are un-maintained or too far off the beaten path, so it should be fine.
Step 1. Download Google Chrome drivers to interface with selenium
This boils down to downloading correct driver for your version of Chrome browser and putting it in the correct location (ex: on Linux put it into /usr/local/bin so it is automatically in the first place your import managers will look in).
If you do not have Google Chrome, download the latest version. Then find out your version of Chrome (open Chrome, click on the 3 dots in the upper right corner, hover cursor over “Help”, click “About Google Chrome”).
Next, go to https://sites.google.com/chromium.org/driver/ and download the chromedriver_linux64.zip of the Google Chrome driver that is compatible with your Google Chrome browser version.
Now extract the driver by running
unzip ~/Downloads/chromedriver_linux64.zip
You should see an executable file named chromedriver in your Downloads folder. Since your import managers will not be looking on your Downloads folder, move this file to /usr/local/bin, which is the customary place to put user-downloaded system-wide affecting files without interfering with other automatically updating packages.
sudo mv ~/Downloads/chromedriver /usr/local/bin
You may read the full selenium installation instructions for troubleshooting advice.
Step 2. Install necessary Python libraries
Data Formatting
Installing pandas, and the correct versions of NumPy and SciPy can be difficult. The official pandas installation instructions recommend installing these as part of the Miniconda distribution.
Web Scraper
conda install -c conda-forge seleniumconda install -c anaconda requestsconda install -c anaconda beautifulsoup4
PDF Text Extraction
pdfminer3
pip install pdfminer3pdftotextsudo apt install build-essential libpoppler-cpp-dev pkg-config python3-devpip install pdftotext
Utilities
- For time estimates on long for-loops:
conda install -c conda-forge tqdm - For easily running script with args from terminal:
conda install fire -c conda-forge - For setting up Jupyter Notebook, follow this article
Create a new folder called dataset in the current directory. This is where data files will be stored. The .gitignore knows to ignore files in dataset/* when syncing with GitHub.
mkdir dataset
Create a new folder called runs in the directory. This is where log files will be stored. The .gitignore knows to ignorelog_* files when syncing with GitHub.
mkdir runs
Create a new folder called save_pdfs in the directory. This is where public notice pdf files will be stored. The .gitignore knows to ignore files in save_pdfs/* when syncing with GitHub.
mkdir save_pdfs
Test: Run a Python script on a single year
Run the python script
python3 scrape_webpages.py --start_date="01/01/1980" --end_date="12/31/1980" --save_string_prefix="dataset/RUN_1980" &> runs/log_1980.txt
Output:
This runs the script and saves the logging output to a plain-text log file.
The script saves data files with the following naming scheme: f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_{table_name}"
The script creates the following tables:
- _table.csv –
- _listing.csv –
- save_pdfs/ –
- _notice.json –
- _notice.csv –
- _gsongso.csv –
- _merge.csv – merge
_table.csv,_listing.csv,_notice.csv,_gsongso.csvon filename - _gso.csv – subsection of
_merge.csvwithis_GSO == 1 - _ngso.csv – subsection of
_merge.csvwithis_NGSO == 1 - _neither_gso_ngso.csv – subsection of
_merge.csvwithis_GSO == 0 & is_NGSO == 0 - _both_gso_ngso.csv – subsection of
_merge.csvwithis_GSO == 1 & is_NGSO == 1
Useful commands:
To see logging in real-time from a different terminal
tail -f log_1980.txt
To read the whole log file
less log_1980.txt
To search for words / ERRORs in log file
grep "ERROR" log_1980.txt
Run: Bash script calling Python script for multiple years
A bash script runs overnight to scrape data from all years in range 1980-2021
sh all_scrape.sh &> runs/log_all_scrape.txt
Each run spans one year of records. All subsequent data files are kept isolated, so that if a run fails, it is easy to redo without affecting other runs. For each step of information extraction, data files are kept separate, so that if steps of a run fail, it is easy to resume with the canned data files from previous steps.
Overview of Functionality
Main Function
The web scraper’s main function is given a time range and a save location. It calls the other functions to automatically perform the web scraping steps.
def main(start_date="01/01/2016", end_date="12/31/2016", save_string_prefix="dataset/RUN_2016"):
# for filenames, replace / with - so file names are valid
start_date_string = start_date.replace("/", "-")
end_date_string = end_date.replace("/", "-")
print(f"SAVE TO: {save_string_prefix}_START_{start_date_string}_END_{end_date_string}")
# name save locations
save_table = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_table.csv"
save_listing = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_listing.csv"
save_pdfs = "save_pdfs/"
save_notice_json = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_notice.json"
save_notice = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_notice.csv"
save_gsongso = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_gsongso.csv"
save_merge = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_merge.csv"
save_gso = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_gso.csv"
save_ngso = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_ngso.csv"
save_neither_gso_ngso = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_neither_gso_ngso.csv"
save_both_gso_ngso = f"{save_string_prefix}_START_{start_date_string}_END_{end_date_string}_both_gso_ngso.csv"
Scrape Table
Go to Date Selection form, generate table for filings acted upon between given start and end date, scrape info from table, aggregate records by file number, and save table to .csv file (Link to FCC Date Selection Form)
# scrape table
scrape_table(start_date, end_date, save_table)
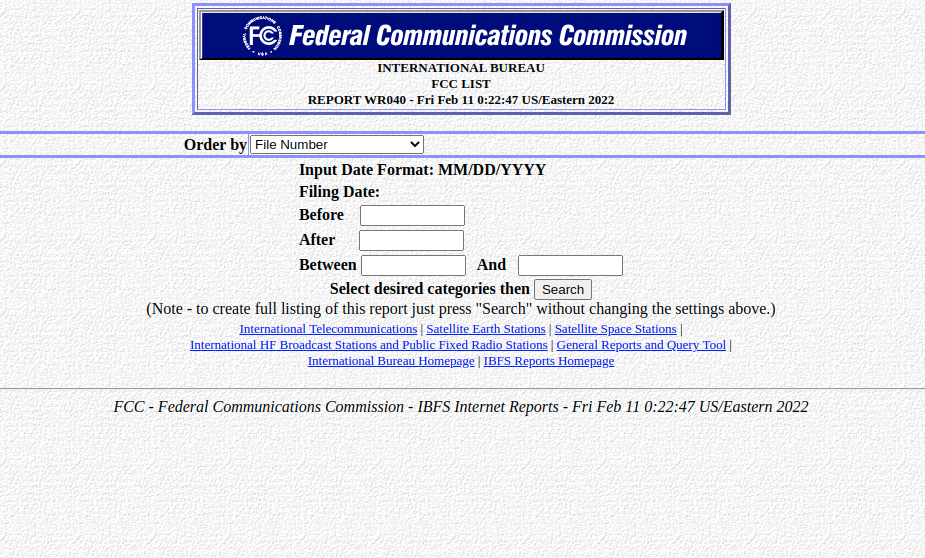
Date Selection Form
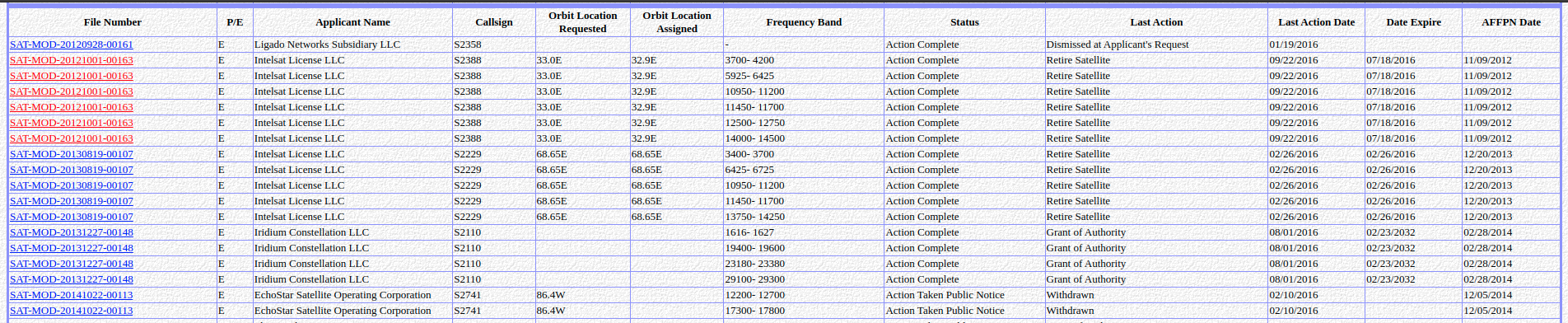
Example Table
Scrape Listing
For each file number + listing link in given list, follow to listing link, scrape information, and save results to .csv (example)
# get file numbers and listing links
list_of_filenumbers, list_of_listing_links = get_list_of_listing_links(save_table)
# scape listing
scrape_listing(list_of_filenumbers, list_of_listing_links, save_listing)

Example Listing
Scrape Public Notices
For each file number + public notice list link in given list, follow the public notice list link, scrape information from table and save the as a .json (example).
# get file numbers and public notice list links
list_of_filenumbers, list_of_public_notice_list_links = get_list_of_public_notice_list_links(save_listing)
# scrape notice
scrape_public_notice_list_a(list_of_filenumbers, list_of_public_notice_list_links, save_pdfs, save_notice_json)
scrape_public_notice_list_b(list_of_filenumbers, list_of_public_notice_list_links, save_pdfs, save_notice_json)
# extract info from saved json
extract_content_from_public_notice(list_of_filenumbers, save_notice_json, save_notice)
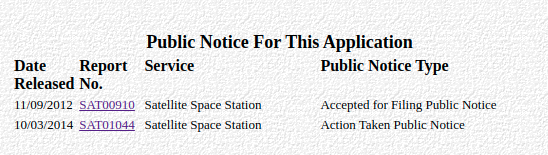
Example Notice List
For each file number + public notice list link in given list, download and open public notice pdfs from report link, extract description text, and save as .json

Example Notice
Extract out certain segments of the PDF text. This is natural text. Regular expressions (RegEx) are used for selecting text that matches a given pattern. Open .json with public notice description text, create data frame with extracted properties, save to .csv
Properties extracted from public notice description text:
- redirects
- outside redirects (outside of the list_of_filenumbers, i.e. were not changed) within the operating date range.)
- frequency band
- frequency band with descriptor (Earth-to-Space, Space-to-Earth)
- orbit location
- waivers
- Callsigns (TODO)
- Policy implications (TODO)
Scrape GSO and NGSO Label
Mark GSO and NGSO types by checking against Search Form, save data frames to .csv files (Link to Advanced Search Form)
# get file numbers and listing links
list_of_filenumbers, list_of_callsigns = get_list_of_callsigns(save_table)
# scrape gso ngso
scrape_gso_ngso(list_of_filenumbers, list_of_callsigns, save_gsongso)
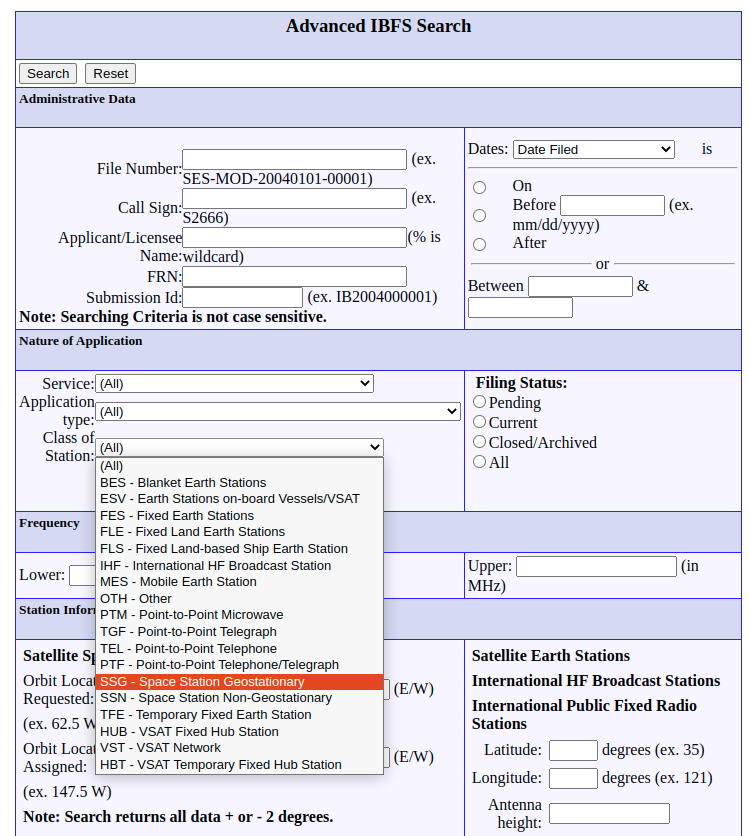
Advanced Search Form
Merge Tables
Merge TABLE, LISTING, NOTICE, GSONGSO data frames by filename as key. Flag any discrepancies
- Flag if Call Sign does not exist
- Flag if Call Sign exists in data table and not in pdf-description or vice-versa
- Flag if frequency exists in data table and not in pdf-description or vice-versa
- Flag if orbital location exists in data table and not in pdf-description or vice-versa
# merge tables
merge_tables(list_of_filenumbers, save_table, save_listing, save_notice, save_gsongso, save_merge)
Save Separate Tables For Review
Split the entire table into GSO and NGSO data frames. Save the tables to “marked as GSO”, “marked as NGSO”, “marked as GSO and NGSO”, and “marked as neither”.
# split into gso, ngso
split_gso_ngso(save_merge, save_gso, save_ngso, save_neither_gso_ngso, save_both_gso_ngso)
Known Errors & Solutions
Sometimes information is not scraped because the FCC website is temporarily down. The recommended solution is to log instances of bad links and at a later time rerun partial web scrape for just the missing data or manually retrieve the information.
There are two types of errors:
- un-handled errors stop the script and their error logs are recorded in the
runs/log_all_scrape.txt. - handled errors do not stop the script, and their error logs are recorded in
runs/log_{year}.txtfor that specific call to the python script
Dealing with un-handled errors
Ideally, all errors would be handled, but scripts are not perfect and the FCC website is unstable. While there is error-handling code in place, in some cases, it makes more sense to stop the run and re-try the web scrape later when the FCC website is more stable. Since the data files are canned as checkpoints, commenting out steps in the Python script before the error happens will save time on re-runs. In the final saved data set, there are no unresolved un-handled errors.
Error Type 1
Public notice PDF was not fetched because FCC website was so unstable that it did not even give the error message for being unable to fetch a public notice PDF resource. Solution: manually download the public notice pdf and re-run python script from the call to scrape_public_notice_list_b
Error Type 2
GSO/NSGO flags were not recorded because the FCC website was so unstable that it did not load a found/not-found message for a constrained advanced search even after 3 repeat tries. Solution: re-run python script from the call to scrape_gso_ngso
Way towards solution
find interrupted runs by seeing what runs/log_{year}.txt logs terminated unexpectedly
# view last five lines for runs in 1980-1999
tail -n 5 runs/log_1*
# view last five lines for runs in 2000-2021
tail -n 5 runs/log_2*
Successful run output (examples: 2001, 2002):
==> runs/log_2001.txt <==
merge table saved to dataset/RUN_2001_START_01-01-2001_END_12-31-2001_merge.csv | length: (192, 51)
gso saved to dataset/RUN_2001_START_01-01-2001_END_12-31-2001_gso.csv | length: (80, 51)
ngso saved to dataset/RUN_2001_START_01-01-2001_END_12-31-2001_ngso.csv | length: (20, 51)
neither saved to dataset/RUN_2001_START_01-01-2001_END_12-31-2001_neither_gso_ngso.csv | length: (92, 51)
both saved to dataset/RUN_2001_START_01-01-2001_END_12-31-2001_both_gso_ngso.csv | length: (0, 51)
==> runs/log_2002.txt <==
merge table saved to dataset/RUN_2002_START_01-01-2002_END_12-31-2002_merge.csv | length: (178, 51)
gso saved to dataset/RUN_2002_START_01-01-2002_END_12-31-2002_gso.csv | length: (88, 51)
ngso saved to dataset/RUN_2002_START_01-01-2002_END_12-31-2002_ngso.csv | length: (16, 51)
neither saved to dataset/RUN_2002_START_01-01-2002_END_12-31-2002_neither_gso_ngso.csv | length: (74, 51)
both saved to dataset/RUN_2002_START_01-01-2002_END_12-31-2002_both_gso_ngso.csv | length: (0, 51)
Interrupted run output (examples: 2003, 2004):
==> runs/log_2003.txt <==
* pn 1/2
* Report No. SAT00167 Report Link https://licensing.fcc.gov/ibfsweb/ib.page.FetchPN?report_key=335209
- - - - - - - - -
==> runs/log_2004.txt <==
312 SAT-T/C-20040910-00173 nan
313 SAT-T/C-20040924-00190 nan
314 SAT-T/C-20041216-00222 S2367
315 SAT-WAV-19980803-00061 nan
316 SAT-WAV-20010302-00018 AMSC-1
Find what step was interrupted by searching the interrupted run’s log runs/log_{year}.txt (depends on keyword search)
Find unhandled error messages by searching for interrupted run’s logs within runs/log_all_scrape.txt (depends on keyword search)
Dealing with handled errors
Handled errors flag when the script skipped past scraping a part of the unstable website. This flagging is helpful for (1) deciding whether to re-run or (2) stick to manual correction. This is how to interpret and handle the handled error messages:
Error Type 1
Invalid / Broken public notice pdf download link. The script asked the FCC to fetch a public notice PDF, but the FCC gave a HTML-file error template instead. The script tried and failed to open the downloaded file with two pdf-opening tools (pdfminer3, pdftotext). Recommendation: try to manually download the public notice pdf (i.e. replace save_pdfs/SAT00001.pdf with a real downloaded public notice pdf) and re-run the script.
ERROR: pdfminer3 could not open pdf save_pdfs/SAT00001.pdf because the FCC pdf download link is broken.ERROR: pdftotext could not open pdf save_pdfs/SAT00001.pdf because the FCC pdf download link is broken.ERROR! Could not find SAT-MOD-19970130-00012!
There are 10 public notice links that are suspected to be permanently broken
- SAT00001
- SAT00019
- SAT00832
- SAT01525
- SAT01530
- SAT01524
- SAT01531
- SAT01523
- SAT01589
- SAT01526
Go to the Advanced Search Form, search the file number, go the listing page, go to the public notice list, and check if the link is still broken. If it is not broken, you can download the pdf.
| year | file number | public notice |
|---|---|---|
| 1998 | SAT-MOD-19970130-00012 | SAT00001 |
| 2004 | SAT-STA-19980812-00064 | SAT00001 |
| 2004 | SAT-WAV-19980803-00061 | SAT00001 |
| 1999 | SAT-ASG-19990527-00059 | SAT00019 |
| 1999 | SAT-STA-19990525-00056 | SAT00019 |
| 2000 | SAT-AMD-19990601-00060 | SAT00019 |
| 2000 | SAT-LOA-19990601-00061 | SAT00019 |
| 2001 | SAT-AMD-19990526-00057 | SAT00019 |
| 2001 | SAT-AMD-19990526-00058 | SAT00019 |
| 2009 | SAT-MOD-19990603-00062 | SAT00019 |
| 2012 | SAT-T/C-20100112-00008 | SAT00832 |
| 2012 | SAT-T/C-20100112-00008 | SAT00832 |
| 2021 | SAT-MOD-20201222-00150 | SAT01523 |
| 2021 | SAT-STA-20201218-00147 | SAT01523 |
| 2021 | SAT-MOD-20200805-00091 | SAT01524 |
| 2021 | SAT-MOD-20200805-00091 | SAT01524 |
| 2021 | SAT-MPL-20201231-00155 | SAT01524 |
| 2021 | SAT-MPL-20201231-00156 | SAT01524 |
| 2021 | SAT-MPL-20201231-00158 | SAT01524 |
| 2021 | SAT-MPL-20201231-00159 | SAT01524 |
| 2021 | SAT-STA-20201112-00135 | SAT01524 |
| 2021 | SAT-STA-20201211-00143 | SAT01524 |
| 2021 | SAT-T/C-20201224-00151 | SAT01524 |
| 2021 | SAT-LOA-20200907-00105 | SAT01525 |
| 2021 | SAT-STA-20210106-00003 | SAT01525 |
| 2021 | SAT-STA-20210111-00006 | SAT01526 |
| 2021 | SAT-MOD-20200526-00057 | SAT01530 |
| 2021 | SAT-STA-20201210-00140 | SAT01530 |
| 2021 | SAT-STA-20201210-00141 | SAT01530 |
| 2021 | SAT-STA-20210127-00015 | SAT01530 |
| 2021 | SAT-MOD-20201201-00138 | SAT01531 |
| 2021 | SAT-STA-20210115-00011 | SAT01531 |
| 2021 | SAT-MOD-20210618-00082 | SAT01589 |
| 2021 | SAT-STA-20210802-00093 | SAT01589 |
| 2021 | SAT-STA-20211018-00131 | SAT01589 |
| 2021 | SAT-STA-20211022-00132 | SAT01589 |
| 2021 | SAT-T/C-20210817-00104 | SAT01589 |
Error Type 2
The public notice pdf was successfully downloaded, but strange formatting issues make the automatic extraction code fail. Recommendation: perform manual extraction of public notice pdf description text. This hit 6 public notices (8 file numbers).
| year | file number | public notice |
|---|---|---|
| 2004 | SAT-MOD-20031118-00333 | SPB200 |
| 2006 | SAT-LOA-20051221-00267 | SAT00335 |
| 2006 | SAT-RPL-20051118-00233 | SAT00335 |
| 2010 | SAT-MOD-20100212-00027 | SAT00667 |
| 2013 | SAT-PDR-20070129-00024 | SAT00422 |
| 2018 | SAT-PDR-20161115-00112 | SAT01231 |
| 2020 | SAT-PDR-20191017-00115 | SAT01433 |
| 2020 | SAT-PDR-20191017-00116 | SAT01433 |
Error Type 3
3 attempts on a GSO/NGSO advanced search timing out. This turns into an un-handled error because this notes a period of unusual FCC website in-stability. Solution: re-run the script at a later time, when the FCC website is more stable.
time out happened 3x on NGSO check on SAT-PPL-20210108-00005
Find the errors:
# view flagged errors in runs 1980-1999
grep -i -n "error" runs/log_1*
# view flagged errors in runs 2000-2021
grep -i -n "error" runs/log_2*
Jupyter Notebook Prototype
We used Python Jupyter Notebook to for easy prototyping quick interactive debugging.
jupyter notebook Interactive.ipynb
To scrape a different date range, change the variables in the first cell.
before_date=""
after_date=""
start_date="1/1/2016"
end_date="12/30/2016"
Credits
Made by Gati Aher and Philip Post for Olin Satellite & Spectrum Technology Policy (OSSTP).